반응형
개념
트리의 순회와 같이 그래프의 모든 정점들을 특정한 순서에 따라 방문하는 알고리즘들을
그래프의 탐색(search) 알고리즘이라고 한다
깊이 우선 탐색(DFS; depth-first search)은 그래프의 모든 정점을 발견하는 가장 단순하고 고전적인 방법이다
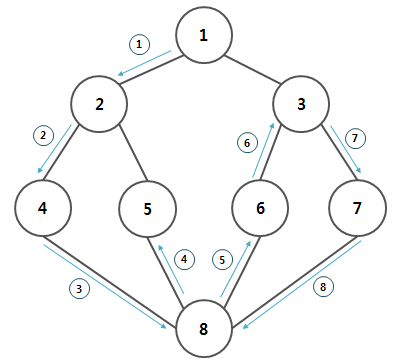
- 현재 정점과 인접한 간선들을 하나씩 검사하다가,
- 아직 방문하지 않은 정점으로 향하는 간선이 있다면 따라가고,
- 더이상 갈 곳이 없다면 포기하고 마지막에 온 간선을 따라 뒤로 돌아간다
3번의 과정에서 우리는 재귀 호출을 이용하여 간단하게 구현할 수 있다
코드
인접 리스트
import java.util.ArrayList;
import java.util.Scanner;
class DfsGraph {
private int nV; // 정점의 개수
private ArrayList<ArrayList<Integer>> adj; // 그래프
private boolean[] visited; // 정점 방문 여부 확인 배열
// 그래프 초기화 생성자
public DfsGraph(int nV) {
this.nV = nV; // 정점 개수 초기화
this.adj = new ArrayList<ArrayList<Integer>>(); // 그래프 생성
for(int i=0; i<this.nV+1; i++) {
this.adj.add(new ArrayList<Integer>());
}
this.visited = new boolean[this.nV+1]; // 방문 여부 확인 배열 생성
}
// 그래프 모든 정점 방문
public void dfsAll() {
// 모든 방문 초기화
for(int i=0; i<this.visited.length; i++) {
this.visited[i] = false;
}
for(int i = 0; i < adj.length; ++i)
if(!visited[i])
dfs(i);
}
// 그래프 탐색 (재귀호출)
public void dfs(int here) {
System.out.println("DFS visits " + here);
this.visited[here] = true;
for(int i : this.adj.get(here)) {
int there = adj[here][i];
if(!visited[there]) {
dfs(there);
}
}
}
// 그래프 추가 (양방향)
public void put(int u, int v) {
this.adj.get(u).add(v);
this.adj.get(v).add(u);
}
// 그래프 추가 (단방향)
public void putSingle(int u, int v) {
this.adj.get(u).add(v);
}
}
인접 행렬
import java.util.Scanner;
class DfsGraph {
private int nV; // 노드의 수
private int[][] adj; // 인접한 그래프
private boolean[] visited; // 정점 방문 여부 확인 배열
// 그래프 초기화
public DfsGraph(int nV) {
this.nV = nV;
this.adj = new int[this.nV+1][this.nV+1];
}
// 그래프 모든 정점 방문
public void dfsAll() {
this.visited = new boolean[this.nV+1];
for(int i = 0; i < adj.length; ++i)
if(!visited[i])
dfs(i);
}
// 그래프 탐색 (재귀호출)
public void dfs(int here) {
System.out.println("DFS visits " + here);
this.visited[here] = true;
for(int i = 0; i < this.adj[here].length; ++i) {
int there = adj[here][i];
if(dfsGraph[here][i] == 1 && !visited[there]) {
dfs(there);
}
}
}
// 그래프 추가 (양방향)
public void put(int u, int v) {
// 정점 u와 v가 연결되어있음을 의미
this.adj[u][v] = this.adj[v][u] = 1;
}
// 그래프 추가 (단방향)
public void putSingle(int u, int v) {
this.adj[u][v] = 1;
}
}
그래프가 하나의 컴포넌트로 이루어져 있다는 보장이 없기 떄문에,
우리는 dfsAll()로 그래프 전체의 구조를 파악할 수 있다
시간 복잡도
인접 리스트를 이용했을 때,
모든 정점을 한 번씩, 간선을 1번 (무향 그래프일 경우 2번) 확인하므로
O(|V| + |E|) 가 된다
(|V|는 정점 수, |E|는 간선 수)
인접 행렬을 사용한다면 dfs() 내부에서 다른 모든 정점들을 순회하며 간선을 확인하므로
O(|V|^2) 가 된다
장점 및 단점
장점
- 구현이 너비 우선 탐색(BFS) 보다 간단하다
- 현재 경로상의 노드들만 기억하면 되므로, 저장 공간의 수요가 비교적 적음
단점
- 모든 정점, 간선을 탐색하므로 검색 속도는 너비 우선 탐색(BFS) 보다 느림
- 해가 없는 경우에 빠질 가능성이 있음
(이러한 경우 사전에 임의의 깊이를 지정한 후 탐색하도록 하고, 목표 노드를 발견하지 못할 경우 다음 경로를 탐색하도록 함 : 점점 깊어지는 탐색(IDS; Iteratively Deepening Search)) - 깊이 우선 탐색은 해를 구하면 탐색이 종료되므로, 구한 해가 최단 경로가 된다는 보장이 없음
(목표에 이르는 경로가 다수인 경우 구한 해가 최적이 아닐 수 있음)
참조 : freestrokes.tistory.com/88 / 알고리즘 문제 해결 전략
더 나아가기 키워드
- 위상 정렬(DAG; directed acycle graph) : visited[] 역순 출력
- 오일러 서킷 : 모든 간선을 한 번씩 지나 시작점으로
- 무향 그래프 : 모든 정점이 짝수점이고 하나의 컴포넌트로 이루어져 있다
- 방향 그래프 : 나가는 간선의 수 == 들어오는 간선의 수 - 오일러 트레일 : 시작점과 끝점을 임의로 이어 오일러 서킷 찾기
- DFS 스패닝 트리(Spanning Tree) : discovered[] 발견 순서로 간선 파악 / finished[] dfs(i) 종료 여부
- 트리 간선 (tree edge) : 스패닝 트리의 모든 간선
- 순방향 간선(forward edge) : 트리 간선이 아닌, 선조-자손 간선
- 역방향 간선(back edge) : 자손-선조 간선 (무향엔 순방향 == 역방향)
- 교차 간선(cross edge) : 나머지 간선 (무향엔 없다) - 절단점(cut vertex) 찾기 : 삭제하면 컴포넌트가 쪼개지는 정점
:임의의 정점 u의 자손들이 모두 역방향 간선으로 u의 선조로 올라간다면,
u는 절단점이 아니다 (discovered[] 이용) - 다리 찾기 : 삭제하면 컴포넌트가 쪼개지는 간선
: 다리는 항상 트리 간선이다
: 다리 (u, v) : 역방향 간선 중 부모 간선 제외,
v와 그 자손들에게서 닿을 수 있는 정점의 최소 발견 순서가 u 후라면 다리 - 강결합 컴포넌트(SCC; strongly connected components)
: 방향 그래프에서 두 정점 u와 v에 대해 양 방향으로 가는 경로가 모두 있을 때,
“SCC에 속해 있다”
: 교차 간선을 따라가 만난 정점의 SCC 묶임 여부를 확인한다
(절단점 판단 알고리즘과 비슷함)
: scc() 함수 - DFS에서 방문한 정점들의 번호를 담는 스택
반응형
'Algorithm' 카테고리의 다른 글
| [C] 깊이 우선 탐색(DFS; Depth First Search) 개념 및 정리 (0) | 2021.02.05 |
|---|---|
| [Java] 너비 우선 탐색(BFS; Breadth First Search) 개념 및 정리 (0) | 2021.01.21 |
| [Python] KMP 알고리즘 (문자열 검색 알고리즘) (0) | 2021.01.05 |
| [C] 우선순위 큐와 힙 (priority queue / heap), 힙 정렬 (Heapsort) (0) | 2020.12.19 |
| [C] 트리 회전 (0) | 2020.12.16 |



